关键词<div center"="">
 常见疑问列举
常见疑问列举<div center"="">

1. FEN串
FEN(Forsyth-Edwards Notation)是一种记录象棋局面的方法,是局面码,源自国际象棋。只需要一串字符串就可以代表一个局面,非常方便,引擎接收局面也是靠FEN。
1.1 FEN的记录规则:
(1)先开始从黑方底线记录,一直到红方底线;红方视角下每条横线从左到右记录。
(2)字母代表子力:k帅将 a士 b象 c炮 n马 r车 p兵卒,大写字母代表红方的子,小写字母代表黑方的子。
(3)遇到空格时,记录连续的空格数。
(4)一条横线记录完后,以/结束,然后开始记录下一条横线。最后一条横线(红方底线)记录完时,不要写/。
(5)全部横线记录完后,写一个空格,然后写w或者b(w红先,b黑先),也有用r代表红先的写法。
1.2 FEN串举例
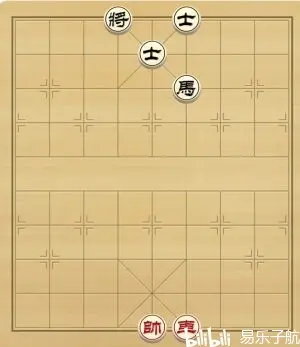
如图的FEN是 3k1a3/4a4/5n3/9/9/9/9/9/9/4KR3 w
看图,先从黑方底线开始,从左到右,第一、二、三格是空的,因为连续3个空,所以先记一个3。然后是黑将,记为k,接着又是一个空格和黑士,记1a。然后又是连续3个空,记3。至此黑方底线记录完毕,再写一个/,这就是第一段3k1a3/的由来。然后依据这个规则记录一直到红方底线记完,注意红方子力用大写字母表示。最后空格加w,w代表红先走。<div center"="">
注:加上代表未吃子步数和代表当前回合的字符,就构成完整的字符串,不再赘述。
1.3 movelist串
FEN代表一个局面,FEN+movelist表示历史着法信息。
movelist是坐标→坐标记录,从红方视角,从左到右所有的纵线记为a到i,从下到上所有横线(红底线到黑底线)记为0到9,至此90个点位都有一个坐标对应。比如,g0f0指g0位置的子移动到了f0。
2.引擎
引擎的功能是计算分析棋局。 常见的有皮卡鱼、阿尔法猫、棋天大圣、名手、newGG、小虫、象眼、旋风等等。
3.界面
界面的主要功能是让引擎和用户之间更方便地沟通。界面也叫GUI(Graphical User Interface)。界面可以理解为充当一个翻译的角色。
常见的界面电脑象棋界面有鲨鱼、兵河、勇芳、T等等。 手机象棋界面有优步、Xchess等等。
界面可以内置棋谱、读库、打谱、读谱等,对绝大多数人来说,界面比引擎更直观接触,常常混为一谈。
4.指令集
以皮卡鱼为例,bmi2和avx2就是指令集。引擎的计算依赖电脑CPU,而指令集一定程度上决定计算的效率。不同指令集只有速度的区别。
对于nnue引擎来说,vnni512、avx512、avx2、bmi2的速度比其余指令集快,具体哪个快,和自己电脑的CPU有关,可以进行bench测速,用数据说话。
另外一般情况下,大多数CPU不支持vnni512和avx512指令集,部分老CPU不支持avx2和bmi2。
bench测速方法:直接双击点开引擎的exe,然后输入 bench,然后回车,最下端会出现相关数字,越大说明速度越快。
5.引擎打分
引擎打分没有绝对标准,所以不同引擎不同版本的分数不能互相比较。分数只能和同版本同引擎的分数内部比较。
引擎的分数如何,和所谓“敏感度”“虚高”没有丝毫关系。引擎棋力的唯一指标是科学的测试数据。一种统一的标准是:根据测试数据做出一个胜率模型,把引擎输出的原始分数转换成胜率分数。比如,目前皮卡鱼的胜率分是和ELO挂钩,200分代表76%胜率(象棋届常说的胜率,也就是胜局加上一半的和局)
引擎的非绝杀分不代表必胜,这些分数只是“评估”。
6.UCI选项
以皮卡鱼为例,皮卡鱼的部分选项说明:
Clear Hash代表清除引擎目前的哈希记忆。不过最常见的是直接重新加载引擎达到这个效果。
MultiPV代表多主变思考。引擎分析局面时默认是1个主变。当改变此选项,引擎分析时会增加当前局面的主变数量,各主变的深度一致,并同时显示,调高数字将会降低棋力,仅供拆棋分析使用。设置范围1~500,默认是1,即只有一个主变。
Skill Level代表限制引擎的棋力水平,设置非20时,有一定概率在出招时选择劣变(同时会开启MultiPV=4)可用作人软对弈。注意仅仅是引擎出招选择劣变,引擎分析和MultiPV=4相同。设置范围0~20,默认为不限制棋力的20。
UCI_Elo代表更细致地限制引擎的棋力水平。只有开启UCI_LimitStrength才会生效,设置范围1280~3133,越低越弱。如果不满足Skill Level的21个级别划分,想要更加细致地划分引擎棋力水平,使用UCI_Elo即可。和Skill Level的限制棋力方式没有区别,只是更加细分。UCI_Elo的值和象棋引擎联赛天梯图校准。
Sixty Move Rule代表60回合自然限招规则。默认开启。开启时引擎将会考虑到60回合不吃子判和,把60回合不吃子视为0分,可以有效提高棋力。需要说明的是如果发现莫名其妙的送子问题,很可能就是此选项导致,说明和你下棋平台或界面的60规则不兼容,可以选择关闭。
Rule60MaxPly代表60回合自然限招的步数设置,设置范围1到120,默认为120,注意这里不是回合,是每步,120步就是60回合。
Mate Threat Depth代表判断中规里“杀”的回合数。该选项只在Repetition Rule里设定为ChineseRule时才会生效,设置范围0~10,设置0则引擎不会判断“杀”。设置1~10,则引擎会在搜索中判断循环招法是不是1~10回合内的“杀”,而“杀”在中规里可能导致循环违规。设置得越高棋力下降越严重。适合纯人在中规环境下拆棋。
Repetition Rule,其中AsianRule是亚洲规则,违规严重级:长将>长捉同一子>其他。SkyRule是某些网络规则,人称天规,是亚规基础上稍作修改的,并不是中规。ComputerRule是基于皮卡鱼作者《中国象棋程序竞赛规则》的规则,和AsianRule有些许出入,也和所有网络平台规则都有较大差异,但是是唯一一个全部符合所有亚规图例结果裁决的规则,更严格按照亚规文字定义。ChineseRule是极简化的中国规则,本质上是亚规改版。注意目前几乎没有网络平台使用中规!且目前中规由于定义过度模糊且复杂,复杂棋例比较依赖裁判的主观想法,绝无任何可能程序化。违规严重级:长将>长捉、长杀、将杀循环、将捉循环、杀捉循环>其他。开启此选项后,Mate Threat Depth不为0时,引擎才会判断“杀”。
AllowChase是只禁止长将,允许其他一切循环着法。因为象棋的规则不统一,所以在一些优势胜势局可以在此规则下进行拆棋分析,以求找到不涉及循环棋规的路线,避开可能存在的循环棋规问题。
UCI_WDLCentipawn代表胜率分数。根据胜率模型,将原始分数转换的分数,关闭会显示原始分数,不影响棋力。目前皮卡鱼的胜率分是和ELO挂钩,200分代表76%胜率。
DrawAsBlackWin是和棋黑胜,引擎会把和棋循环与自然限招和棋算作黑胜。
DrawAsRedWin是和棋红胜。
DrawRepAsBlackWin是和棋循环黑胜,引擎只会把和棋的循环算作黑胜。拆棋分析的时候,不想短期内走出和棋循环可以利用这个。
DrawRepAsRedWin是和棋循环红胜。
EvalFile代表引擎要读取的NNUE权重文件名称与路径。引擎默认读取同一文件路径下名为pikafish.nnue的文件,可以将NNUE文件改名,并且通过此选项使其仍可以被读取。一般人不需要,手机优步可通过此选项达到配置多引擎的效果。
7.开局库
开局库对电脑来说相当于人类的棋谱。引擎只负责计算,和开局库无关,但部分引擎可能有内置的开局库,皮卡鱼无内置开局库。
开局库的作用:
(1)开局库的主要作用是节省时间、减少输棋的概率。
(2)部分开局库还追求引导对手走入复杂的局面、对手开局库的错招、引擎容易出错的局面,来寻求取胜的机会
(3)开局库虽然被叫作开局库,但是就像棋谱一样,任何局面都可以录入,中局局面、残局局面、排局全都可以录入。
(4)开局库和引擎完全独立没有任何配合,引擎本身并不会读取开局库。
8.云库
云库一个免费查询的在线数据库,网址为chessdb.cn。云库收录了极多的局面并用后台服务器计算打分,也有部分残局库。除残局库外,云库所收录的局面分数不一定准确,但计算延伸越多的局面也就越可能准确。
9.残局库
残局库是穷尽某些子力组合的库。例如穷尽“帅VS将”,以此为基础再开始穷尽“帅兵 vs 将”。如果要搞出车对双马的残局库,那么必须先搞好帅对将、帅对马、帅对双马、帅车对将、帅车对马的残局库。残局库先穷尽一个子力组合的所有局面,然后提取所有取胜局面,再提取被将死方无法阻止将死方将死的所有局面,如此倒推,推出所有的理论必胜必负局面,最终推不到的局面都是和棋。
在残局库的规则下,如果没有bug,那么残局库结论是绝对准确的,残局库只有胜负和三种结论。
象棋残局库主要有DTM和DTC两种。DTM的胜方目标只有将死和困毙,败方目标是尽力拖延将死和困毙。而DTC,这里以云库DTC说明。胜方目标是将死、困毙、子力变化,取最短的一项作为目标。还有一个特殊的循环犯规次数,胜方会尽力防止负方循环犯规,如果无法防止,则胜方会走负方犯规次数最少的路径,并且拖延负方犯规。而负方会拖延被将死、被困毙、场上子力变化,并且尽力犯规。DTC因为对目标的步数更短,所以体积比DTM小很多。部分象棋引擎可以配合自己格式的残局库进行搜索。残局库的终极目标是全子残局库。
10.审局库
审局库就是残局库,但没有着法。残局库会告诉局面的结论和胜局的取胜着法,而审局库只会告诉局面的结论(胜 负 和)。 但因此,使得审局库的体积比残局库小很多。常见误区是审局库是关于中局的,这是被"审局"的名字误导了,其实作用和残局库是一样的。因为审局库只有结果信息没有着法信息,所以某些复杂定式必胜残局,即使引擎和审局库配合搜索也难以取胜,例如一个复杂定式必胜残局,引擎搜索的局面绝大多数都是审局库的“胜”,那么这和没有审局库也差不多,只不过引擎不需要把搜索算力浪费在那些“和”“负”的局面上。
11.nnue权重
nnue是一种神经网络的架构,适合CPU处理器推理。现在象棋顶级引擎都使用nnue,nnue仅是评估网络,只负责评估局面。而现在象棋顶级引擎使用的搜索算法,仍然是传统的ab剪枝搜索。
12.传统引擎
传统引擎指的是使用传统评估(或称手工评估),而非神经网络评估的引擎,如名手326、NewGG、2020年9月之前的旋风等等。传统引擎的上限棋力比NNUE引擎弱很多,但搜索速度比NNUE引擎快。传统评估是人手工编写的,具有可解释性(就是可以解释每种评估的意义,例如每个子力是几分、车在什么位置有加分或扣分、将帅在高位扣分,窝心马扣分),而基于神经网络的评估不可解释。
简单的传统评估通常子力价值和考虑子力位置的PSQT进行评估,复杂的传统评估可以考虑子力自由度、子力牵制、将帅安全等。
13.评估
评估就是对局面的评估。类似于人类对一个局面的直觉,不进行任何棋局计算,就是纯感觉局面的优劣,也可以叫“审局”。只不过引擎的评估会按照它的评估参数,来计算出局面的分数。在nnue之前,评估都是靠人类写的,并且调整参数。例如写最基础的子力价值:车x分、马x分....,然后再调整参数的数值。另外还有子力位置分、子力机动性分数、特殊棋型的分数等等。nnue完全代替了传统的手工评估,nnue相当于有海量的评估参数,但是人类不知道那些参数代表什么。nnue会导致引擎的搜索速度变慢,但是因为利远大于弊,所以棋力依然是飞跃提升。
14.等级分
ELO评分系统是一个广泛应用于多个竞技领域(如棋类游戏)的排名方法,它可以用来为多个参赛者(例如棋手或引擎)进行排名并量化它们之间的实力差异。ELO系统根据参赛者间的胜率来调整分数,使得分数能够直观地反映出他们的实力差距。ELO评分的核心计算公式是1/(1+10^(n/400)),其中n代表两个参赛者之间的ELO分数差。在多个引擎排名中,其中两个引擎遇上,如果引擎A的ELO评分比引擎B高71分,那么根据ELO公式,我们可以计算出A对B的胜率大约为60%(和棋视为半胜半负)。实际比赛结果如果显示A的胜率不足60%,则A的ELO分会下调,B的ELO分相应上升,以更准确地反映两者的实力差异。多个引擎的Elo通常使用Bayeselo、Ordo等工具计算。而在一对一的引擎测试中,ELO就完全可由胜率计算。非一对一的情况下,不同的ELO系统可能因为计算方式不同,系统内的引擎(棋手)不同,比赛方法不同等等因素,导致不同ELO系统间的ELO分数不能互相比较,可以参考强弱关系,但不能直接比较分数。
下篇关键语<div center"="">

(1)为什么引擎解不开某些局面?
评估存在盲区。引擎极难计算某些排局,因为这些排局是人类能掌握并且知道结论的,还有一种类型的局面经常被忽视,但引擎也可能极难算到的,那就是优势开局。在引擎测试中,经常用到优势开局,比如红高优开局,然后两个引擎各执红执黑一次进行对战,会经常出现一胜一和的情况,这些局面引擎可能无法稳定和棋或者稳定取胜,所以也可以是引擎“解不出来”的局面,人类更不可能知道这些优势局究竟是胜还是和。另外,引擎的棋力水平标准只有科学的测试数据,只比较部分局面无法代表引擎的棋力水平。
(2)象棋被穷尽了吗?
远远没有。目前象棋圈软件爱好者跑出来的大残局库子力组合,例如有车炮对马炮士象全(四大子+双士双相)、双马单相对马卒双象(三大子+一兵+三相)、双炮单士相对马缺士(三大子+双士三相)、双马炮单士对车双士(四大子+三士)、炮兵单缺相对炮卒(二大子+二兵+双士一相)等等, 可见距离“穷尽”(十二大子+十兵+四士四相) 极其遥远(指数爆炸)。
(3)引擎计算是使用“穷举法”吗?
不是。主流的CPU引擎均使用ab剪枝搜索,搜索过程中会进行巨量的剪枝。强大的引擎其分支因子不到2,也就是说,搜索到一个局面,从这个局面再往下搜索一次的话,平均搜不到2个着法,剪掉其余几十种着法。而显卡引擎(阿尔法狗的搜索算法)的搜索方法是广义的mcts,用来配合大架构神经网络。搜索的速度和CPU引擎比起来慢极多,更不可能是“穷举”。
(4)神经网络的“自我学习”是什么?
在主流棋类引擎中,神经网络都属于离线监督学习。训练师会先让引擎自对弈,从而生成数据(棋谱)。以nnue跑谱为例,这些数据里面有每步的局面、分数、和这局游戏的结果等等信息,通常是以每步几层或者几千、几万节点自对弈生成。生成了足够多的数据后,便拿去训练,训练过程可以简单理解为去调整神经网络里的海量参数,使得网络的输出接近更数据。比如一个局面100分,训练就会改变神经网络参数让评估分数去接近这个100分。因为是离线学习,依赖作者训练发布,所以你使用引擎是无法让引擎“学习”的(但棋类也完全不适合在线学习),而引擎有哈希表这种暂时的信息储存,所以拆棋时会感觉引擎有记忆功能,但重新加载后便失去了记忆。
(5)如何科学地测试引擎?
科学的引擎测试,要让引擎处于相同的机器下,用一个测试工具、双方测试条件和设置一致、用数量足够多的多样化开局局面、并确保是纯引擎计算出招(部分引擎对主流局面可能有内置开局库),每个局面进行分先测试,最好不要开后台思考,并尽量排除可能的后台程序干扰、排除引擎之间的棋规分歧棋谱与界面和引擎之间的棋规分歧棋谱。最好不用超线程,除非只开一桌而非多开。并且排除可能的多路CPU调度问题。并且测试数量要足够多,避免误差,例如几千局,最好使用统计学工具。如果差距过小甚至要至少几万局。另外,建议采用局时加秒制测试,引擎会根据局面复杂度等信息自行分配思考时间,可以减少不必要的思考,相同用时下的棋力也更强,除非引擎的时间管理太差。测试的作用是放大引擎之间的棋力差异,所以如果引擎棋力接近,一般采用优势局面分先测试,优势局面分先更能放大棋力的差异、减少通过误差所需的时间。
(6)深度(层数)是什么?上层速度代表棋力吗?
对目前的强引擎来说,深度(层数)已经不是真实的“深度”,它和算几步棋没有太大的关系,因为现在的剪枝策略让不同着法的搜索深度很不平衡。 现在显示的深度(层数)只代表搜索迭代了几次,有的着法深度会超过这个数字,大多着法深度会低于这个数字。
上层速度不代表棋力。棋力的唯一指标是科学的测试数据。对一般人来说,如果上层速度和棋局前面比起来明显变慢,可能后续会有比较复杂的变化。 除此之外,大部分意义在于看着舒服。
(7)Nps(k值)是什么?代表棋力吗?
NPS(Nodes Per Second)是每秒平均搜索局面数,可以理解成搜索速度,因为常以K(千)为单位表示,又被称为K值。但速度快慢和棋力没什么大关系,例如nnue拖慢了不少nps,但是棋力仍然比传统评估引擎更强。不同引擎不同版本的nps无法比较,nps只适合比较机器的强弱:相同引擎的相同版本、相同设置,相同的局面的前提下,进行多次测速。测速出的nps越高,代表机器算力也就越高。
nps不代表引擎本身的棋力。棋力的唯一指标是科学的测试数据。并且部分其他引擎或者远程云引擎会放大nps(一般也会放大节点数),使其更加好看,比如乘以6或乘以2.5。皮卡鱼的nps是真实的,如果皮卡鱼的nps只有几十k每秒(也就是几万每秒),那么极有可能不正常,哪里出现了问题。
(8)置换表(哈希)是什么?设置多少好?
置换表的主要作用是搜索过程中会记录一些局面的信息(如分数)到置换表中,之后搜索遇到已在置换表内重复的局面可以直接提取置换表已经储存的结果,节省时间。目前的多线程算法也基于共享置换表实现。理论上来说,在机器剩余运行内存允许的情况下,分析局面是越大越好,但启动计算时可能会出现一下卡顿。
(9)核心或线程越高的机器就越好吗?
通常是。但得看情况,还得主要看架构、频率等。一些机器的核心线程数都不少,但因为架构频率等因素,核心都比现在主流机器核心差很多,而且如果指令集不高级,速度也不尽如人意。比如E5 2660 v2,10核20线程,不支持avx2 bmi2等高级指令集,即使20线程开满,也不如7950x用bmi2跑的3或4核心。硬件决定了引擎搜索的速度。
(10)对象棋引擎来说,机器算力的因素大吗?
实战来说,机器算力的优势较难看出来。因为实战是容错率高的均势局面,且有对起始局面经过大量拆解的开局库,和棋率很高。但不代表算力没有用,得看个人的需求。实战的用时越快,那么算力的优势就更能体现出来。但是如果从测试角度出发,强弱算力的差异是巨大的,测试中为了快速分辨引擎是强弱,会进行分先优势局测试,比如50%和棋率的高优势开局,双方引擎在每个开局分先。这种高优分先的情况下,算力的棋力提升十分可观,比如2线程5分+3秒对1线程, 胜率可达55%以上。
(11)软件对打只能和棋吗?
实战而言,和棋率极高,但总有概率可以分出胜负。
(12)引擎棋力越强,任何局面一定就比弱的引擎好吗?
不一定。棋力强的准确理解是“在更多的局面表现更好”。例如a的棋力比b强,可能有60%的局面a表现更好,10%的局面表现伯仲之间,30%的局面b的表现更好。a的棋力更强,不代表a是b的完全上位。
(13)引擎多核多线程与单核的区别?
其他条件变量都完全相同的情况下,核心算力都一致,那么例如4核1秒的棋力是不如1核4秒的,因为现在的主流多线程搜索算法存在损耗,但是会加宽搜索树,可以理解为:4核1秒大多局面不如1核4秒优越,仍有部分局面更优越于1核4秒。且多线程搜索有搜索不确定,先后搜索同一个局面的结果很有可能是不一样的。 而单线程的搜索,在其他条件相同的情况下,对应深度的思考细节和分数会完全一致。


